
trocco APIを使ってデータパイプライン運用を改善してみた
はじめに
本記事はQiita trocco Advent Calendar2022 20日目の記事です。

troccoとはどのようなサービスなのか
troccoは株式会社primeNumberが開発・運営しているマネージドなEmbulkサービスです。troccoを利用することで従来は非常に手間がかかっていた、様々なシステム・サービス間でのデータ連携や変換処理(いわゆるデータパイプライン処理)を簡単に行うことが可能となります。

troccoを利用してデータパイプライン処理を構築する際には基本的にプログラミング言語などの知識は必要なく、GUI上での操作と基本的なSQLの知識があれば、誰でも本格的なデータパイプラインを構築することができます!!
更にtroccoにはプログラミングETLやtrocco APIといったオプション機能が存在し、これらの機能を活用することで、さらに柔軟にデータパイプラインの構築・運用を行うことが可能となります。
本記事は私が実際にtrocco APIを利用してみた感想と、これからどのように活用していこうと思っているかについて触れた記事となります。
troccoの基本的な機能について
本題に入る前に、まずは簡単にtroccoの機能について簡単にご説明したいと思います。先ほど触れた通りtroccoはマネージドなEmbulkサービスとなっており、GUIの操作とSQLを利用することで非常に簡単にデータパイプラインの構築を行うことができます。troccoでデータパイプラインを構築する際には、主に以下の3つの機能を利用することになります。
- 転送ジョブ
- シンクジョブ
- ワークフロージョブ
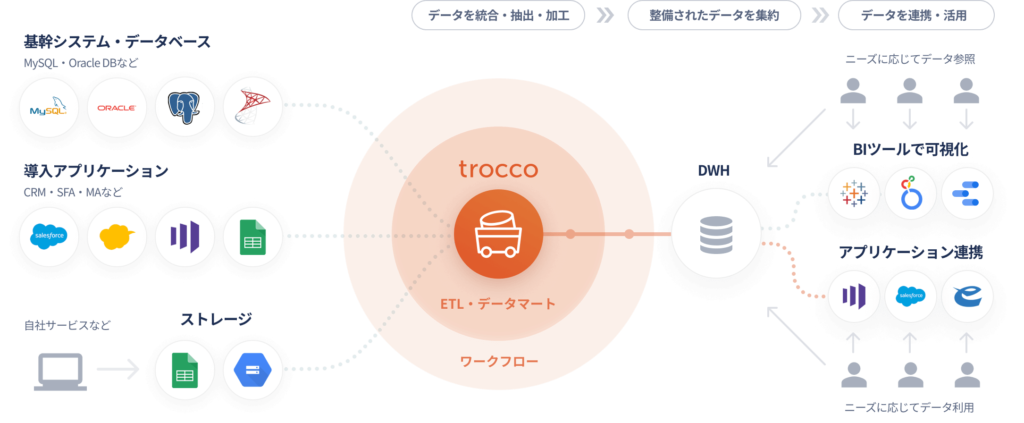
転送ジョブについては、さまざまなデータソースからDWHサービス(BigQuery、Snowflake、Redshiftなど)に対してデータをロードするための連携・加工処理などを行う機能となります。例えばクラウド上のオブジェクトストレージ(S3(AWS)、Cloud Storage(Google Cloud)など)からBigQueryなどのDWHサービスにデータを連携したり、外部のDBMS(MySQL、PostgreSQL)やSaaSサービス(SalesForceなど)から同様にDWHに連携したりするイメージです。
シンクジョブについてはDWH内のテーブル間でのデータ変換や集計処理を行う機能となります。例えばGoogleアナリティクスなどのWebアクセスログや自社ECの会員情報テーブルや注文履歴テーブルのデータなどをBigQuery取り込んだあと、そのままのテーブルだと利用用途が限定されてしまうため、Webアクセスログと会員情報データ、注文履歴データを組み合わせて、顧客の行動履歴の分析や会員属性と商品購入データを組みあわせて、より詳細にお客様の趣向などを分析する場合などにこのシンクジョブを使うと非常に便利です。
イメージとしては以下の図を見ていただければわかりやすいかと思います。
trocco APIについて
ではここから本題となる、trocco APIについて触れていきたいと思います。trocco APIは名前の通り、troccoの管理画面上で操作できる様々な機能について、Web APIを利用して実行することが可能となる便利な機能です。
APIの仕様についてはドキュメントに記載がありますが、以下の機能をtrocco APIで実行することが可能となります。
- 転送ジョブの実行
- 転送ジョブのステータス確認
- ワークフロージョブの実行
- ワークフロージョブのステータス確認
trocco APIの使い方については基本的には普通のWeb APIと同様に対象のエンドポイントに対してHTTPのリクエストとしてPOST、GETメソッドを実行することで、trocco APIの機能を利用することができます。
ドキュメント内の記載例を基に、curlコマンドの実行イメージを記載すると以下の通りとなります。
転送ジョブの実行
転送ジョブの実行については、転送設定ID(ジョブID)に対してPOSTメソッドを発行することでWeb APIの機能を利用することができます。
curlコマンドの場合
$ curl -X POST "https://trocco.io/api/jobs?job_definition_id=[転送設定ID]" \ -H "Authorization: Token [APIキー]" \ -H "Content-Type: application/json" \ --data '{"custom_variables":[{"name": "[カスタム変数名]", "value": "[カスタム変数に設定する値]"}]}'Pythonだとこんな感じでしょうか。
import requests
headers = {
'Authorization': 'Token [APIキー]',
'Content-Type': 'application/json',
}
params = {
'job_definition_id': '[転送設定ID]',
}
json_data = {
'custom_variables': [
{
'name': '[カスタム変数名]',
'value': '[カスタム変数に設定する値]',
},
],
}とてもシンプルですね。私は業務上でプログラムを本格的に書くような仕事はほとんど経験したことがないのですが、上記のようにHTTPのPOST、GETメソッドを投げるだけの処理なら簡単に書けるので安心です。
転送ジョブのステータス確認
GETメソッドではステータスの確認ができます。
$ curl -X GET https://trocco.io/api/jobs/<ジョブID>
-H "Authorization: Token [APIキー]"実際には状況に応じてローカルPCなどからcurlコマンドを直接実行したり、cron経由で実行されるシェルスクリプトでcurlを実行、もしくはCloud FunctionsやAWS LambdaのようなやFaaSサービスを利用してPythonなどのプログラミング言語でAPIを実行するなどの方法が考えられるかと思います。
データパイプラインの運用における課題・trocco APIを導入した経緯について
私が所属している企業はもともとデータ分析基盤自体が存在せず、約2年ほど前から完全に1から設計・構築を始めました。最近になってようやく環境も整ってきたのですが、あまり運用について考慮せず、とりあえず動かすことを第一に構築を進めてきたので、データソースが増えるにつれて運用工数も徐々に増えてきたということが課題となってきました。
特にオンプレ環境からGoogle Cloudに連携されるデータについてはそもそも運用体制が整っておらず連携処理がエラーとなった場合、現状では私が一人で対応する状況になっています・・・ツラい(´;ω;`)ウッ…
運用における具体的な課題としては、例えばtroccoのジョブが実行されるタイミングにデータソース側で想定していたデータが存在していない場合、troccoのジョブがエラーとなりジョブのリカバリが必要となります。この場合については、データソース側のデータを正しく置きなおして再度troccoのジョブを実行することで対応を行っていました。
もともと「とりあえず動くことを第一に」ジョブを作っていたため、リカバリー時についてはいわゆるジョブの切り出し実行(対象のジョブをいったんコピーしてパラメータを変更した上でGUIから転送ジョブまたはシンクジョブのリラン)という、非常に効率が悪い運用を行っていました。
ジョブの本数が少ないうちはこれでも十分対応が可能だったのですが、データソースがそこそこ増えてジョブの本数が増えてくると、わざわざジョブのリカバリーを行うためにGUI上でポチポチ画面をいじってジョブのリランをするのがしんどくなってきます。
このような状況をどうにか改善するために、少しでも効率的にデータパイプラインを運用できるようにするため、trocco APIを導入することにしました。
trocco APIの具体的な利用方法
trocco APIを導入し、実際に取組みを始めたのは以下の2点となります。
- データパイプライン処理のリカバリー作業効率化
- 情報システム部門への業務移管
1つめのリカバリー作業の効率化については、ジョブがエラーになった際にデータソース側のデータを再格納した後、わざわざtroccoの管理画面を開かなくてもローカルのWSL環境からcurlコマンドの実行ができることで、リカバリーにかかる時間が大幅に削減されました。
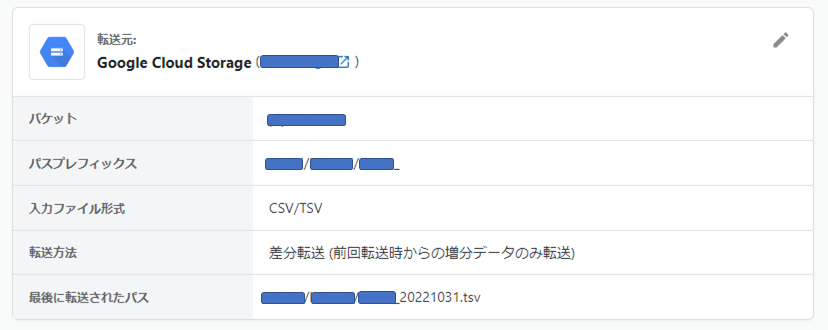
具体的には、Cloud Storage上に “hoge/hoge_[yyyyMMdd].csv” のように日ごとのデータがアップロードされる場合、今まではパスプレフィックスとして “hoge/hoge_” というように設定を行うことで、最新日付のデータを自動でBigQueryにロードできるようにしていたのですが、これだとジョブがエラーになった際に再度、正しいデータを連携させるためのリカバリを行うのに手動でtroccoのジョブをリランしなければなりません。
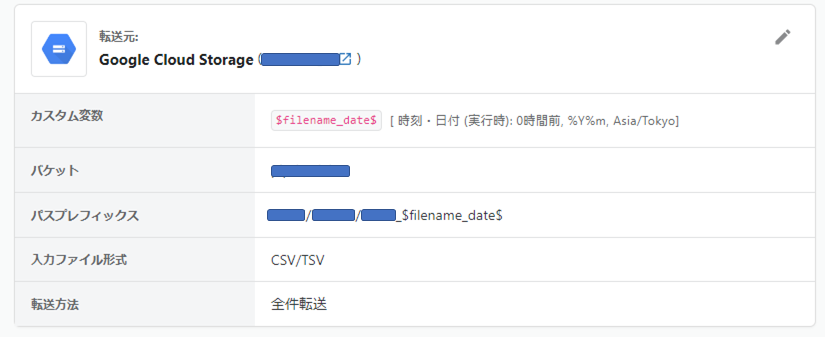
そのため、カスタム変数として$filename_date$のようなカスタム変数を作成し、それをパスプレフィックス上で”hoge/hoge_$filename_date$”のように設定することで、何かエラーがあった際にもローカルのWSL2からcurlコマンドでリカバリを簡単に行うことができるようになりました。
設定はこんな感じ・・・
日々の日次データ連携用の処理についてはファイル日付をパスプレフィックスを利用して最新日付のデータのみをBigQueryに連携します。
以下はエラーが発生した時のリカバリー用のジョブです。カスタム変数として$filename_date$のような変数を作成し、先ほどのcurlコマンドのような形で対象日付を指定して転送ジョブを実行します。
2つめについては、今まで転送ジョブ(ETL処理)とシンクジョブ(ELT処理)の両方ともがほぼ私が所属している部署(非IT部門)で運用していたのですが、オンプレからGoogle Cloudへの連携処理(Cloud SDKで実行)に合わせてtrocco APIを利用した転送ジョブについても情報システム側に移管することで、よりデータマート作成や運用に力を割けるようになるということになります。
現状ではまだリカバリーのみの対応しかできてないですが、今後は日次用のジョブとリカバリー用の転送ジョブを統合して、Cloud SDK実行用のシェルスクリプトで日々の運用+リカバリーを一元的に実行できるように対応を進めたいと考えています。
trocco APIに興味がある方はぜひ触ってみてください!




コメント